通过前面的博客我们了解到LevelDB是一个写性能十分优秀的存储引擎,是典型的LSM树的实现,LSM树写性能极高的原理实际上就是尽量减少随机写的操作,对于每次写入操作并不是直接将最新的数据进行落盘操作,而是将其拆分成两个步骤,首先将当前写入操作转换成一条记录顺序追加到日志末尾,然后将数据插入到内存维护的数据结构当中,等到内存中的数据体积到达一定的阈值,进行刷盘操作,基于这种思路实现的LevelDB确实获得了不俗的写性能,但是却面临如下两个问题
可预见的是,随着数据不断的写入我们如果不采取任何措施,读放大和空间放大问题会越来越严重,LevelDB为了提高读写效率并且降低空间放大的问题引入了Compact机制,这正是本篇博客要介绍的
LevelDB中的Compact可以分为Minor Compact和Major Compact,下面会一一介绍
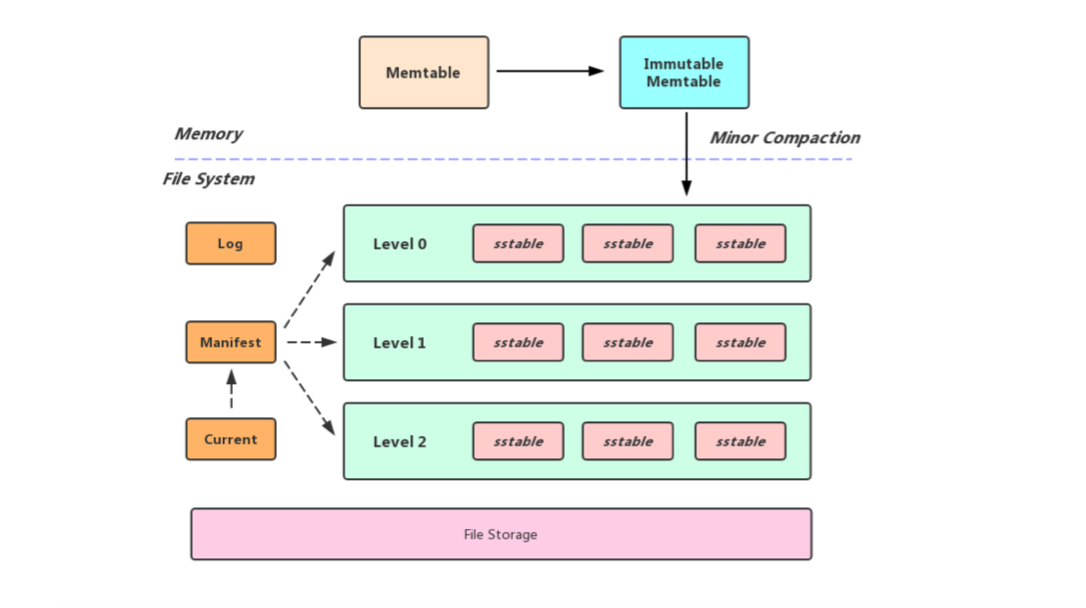
前面的博客提到过,向LevelDB中写数据,首先是写入内存中的Memtable,然后Memtable在一定的条件下(实际上就是Memtable的体积达到了用户设置的write_buffer_size大小)就会转换成Immutable Memtable,而Immutable Memtable就会等待被刷盘, 所以Minor Compact的本质就是将内存数据库中所有数据持久化到一个磁盘文件中
Minor Compact的流程实际上很简单,创建一个迭代器用于迭代Immutable Memtable,在遍历的过程中将获取到的数据写入到一个sst文件当中,这个过程完毕之后将新生成的sst文件放入到Level 0当中, 然后将Immutable Memtable置空, 需要注意的是由于Level 0中的sst文件是由内存中的数据直接生成,所以该层不同的sst文件之间可能有overlap,正是由于有此特性,所以不管是数据查询还是Major Compact对Level 0层都会进行特殊处理
LevelDB中Memtable的体积达到了write_buffer_size, 就会转换成Immutable Memtable(这时会将Memtable置空,允许外界将数据写入新的Memtable当中), 然后后台线程便会执行Minor Compact的操作
Q: Minor Compact既然是后台线程操作,那么会不会存在上次Minor Compact任务还没执行完,新的Memtable又被写满了?
A: 问题是存在的,这种情况下我们只能阻塞等待,也就是常说的阻写操作
如果说Minor Compact的作用是将内存中的数据原封不动的刷到磁盘中然后腾出内存中的空间容纳新的数据,那么Major Compact的作用实际上就是经可能的清理掉无效的数据来缓解读放大和空间放大的问题,Major Compact是作用于相邻Level之间的,在Level层选出待Compact的连续一段区间的sst文件,然后在Level + 1层选出可以完全覆盖Level待Compact的那段区间,接着就是将这些sst文件中的所有条目做一次归并遍历然后将有效的数据输出到新的sst文件当中,最后将新生成的sst文件放入Level + 1层合适的位置中,然后将参与Compact的那些旧sst文件删除即可 (这个过程是比较复杂的,并且LevelDB做了一系列优化操作, 下面会细说)
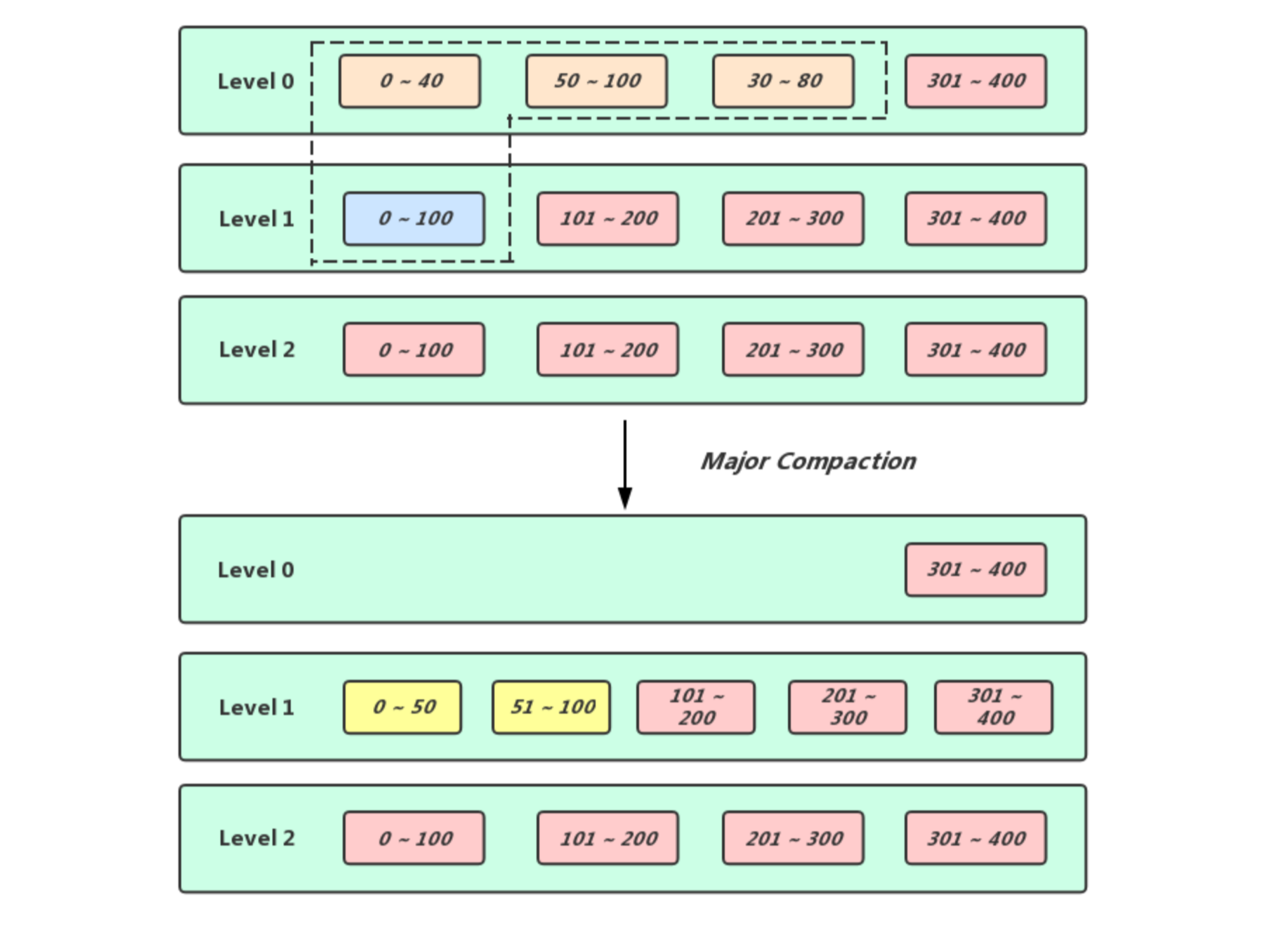
通过体积触发(Size Compaction): 在生成新的Version之前会通过当前Version的sst文件的分布情况为每一个Level计算出一个score值,score值越大表示对应层越需要触发compact,因为Level 0层的sst文件之间可能存在overlap,查询起来开销较其它层要大,我们需要避免在Level 0层存放过多的sst文件,所以Level 0层的score值是按照该层sst文件数量以及kL0_CompactionTrigger(Level 0层最多4个sst文件)计算出来的,对于Level i (i >= 1)来说,一次读取最多只会访问一个sst文件,因此,本身对于读取效率影响不会太大,针对这部分数据发生compact的条件,从提升读取效率转变成了降低compact的IO开销,这种情况score值是根据该层自身所有sst文件体积之和以及该层对应触发Compact的阈值决定的(Level 1层的阈值是10MB,Level 2层的阈值是100MB,依次类推, 某层sst文件的总体积除以该层对应的阈值就是score),遍历了所有Level之后会在当前Version中记录下最大的score值到compaction_score_中以及对应的level到compaction_level_中,如果score的值大于1,那么就需要等待被Compact了
通过Seek触发(Seek Compaction): 在Leveldb内部实际上有一套假设,说是一次Seek花费10ms,读写1MB的数据花费也是10ms,然后对1MB的数据做Compact会花费25MB的IO,所以得出结论说执行一次Seek的代价和Compact 40Kb的数据的代价相等,所以在生成一个新的sst文件时,会通过该文件的体积计算出其最大可以被seek的总次数记录在对应文件的allowed_seeks当中,以后如果通过Get接口执行的查询操作找到了某个sst文件,但是实际上我们所需要的数据并不在这个文件当中,那么该文件的allowed_seeks变量会进行自减操作,如果某个sst文件的allowed_seeks小于等于0了,那么就会将该当前Version中的file_to_compact_指向这个文件,并且令file_to_compact_level_记录这个文件的所在层,等待触发Compact
上面介绍了两种触发Compact的时机,如果是通过体积触发的,我们只需要找到Level层第一个大于该层compact_pointer_的sst文件作为目标文件即可, 如果是通过Seek触发的,那更加简单了,目标文件直接被记录在了Version的file_to_compact_当中(需要注意的是,如果当前是Level 0层触发Compact,那么需要特殊处理一下,要在该层找到其他和目标文件有overlap的sst文件),我们将在Level层选中待Compact的sst文件放入input[0]集合当中
if (last_sequence_for_key <= compact->smallest_snapshot) {
// Hidden by an newer entry for same user key
drop = true; // (A)
} else if (ikey.type == kTypeDeletion &&
ikey.sequence <= compact->smallest_snapshot &&
compact->compaction->IsBaseLevelForKey(ikey.user_key)) {
// For this user key:
// (1) there is no data in higher levels
// (2) data in lower levels will have larger sequence numbers
// (3) data in layers that are being compacted here and have
// smaller sequence numbers will be dropped in the next
// few iterations of this loop (by rule (A) above).
// Therefore this deletion marker is obsolete and can be dropped.
drop = true;
}
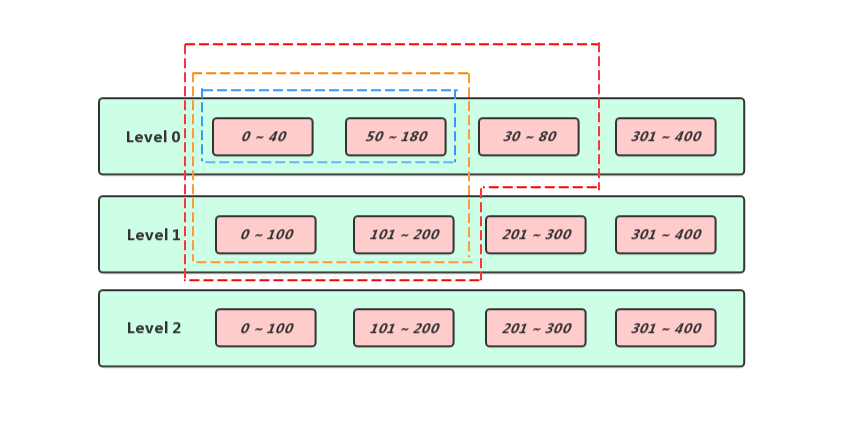
前面介绍过在LevelDB当中如果多条记录具有相同的Key,那么排列在最前面的那个条目序列号一定是最大的,并且存储的数据也是最新的,而排列在后面的那些则是旧数据,理论上是可以被删除的,但是前提是这个条目没有被快照引用,在上面的插图中Seq=20的那条记录是最新的,但由于在Seq=15处打了一个快照,所以只有被紫色矩形括住的条目在可以被drop掉

再考虑另外一种场景,和上面一样有一系列Key相同的条目排列在一起,但是队头的条目是带有删除标记的,这就意味着对应Key是已经被删除的,在没有快照限制的场景下紫色矩形括住的条目实际上都是可以被drop掉的,但是当我们在删除带有kTypeDeletion标记的条目的时候要保证在[level_ + 2, kNumLevels]层这个Key一定没有出现过,否则高Level的对应Key的旧数据可能会变成新数据
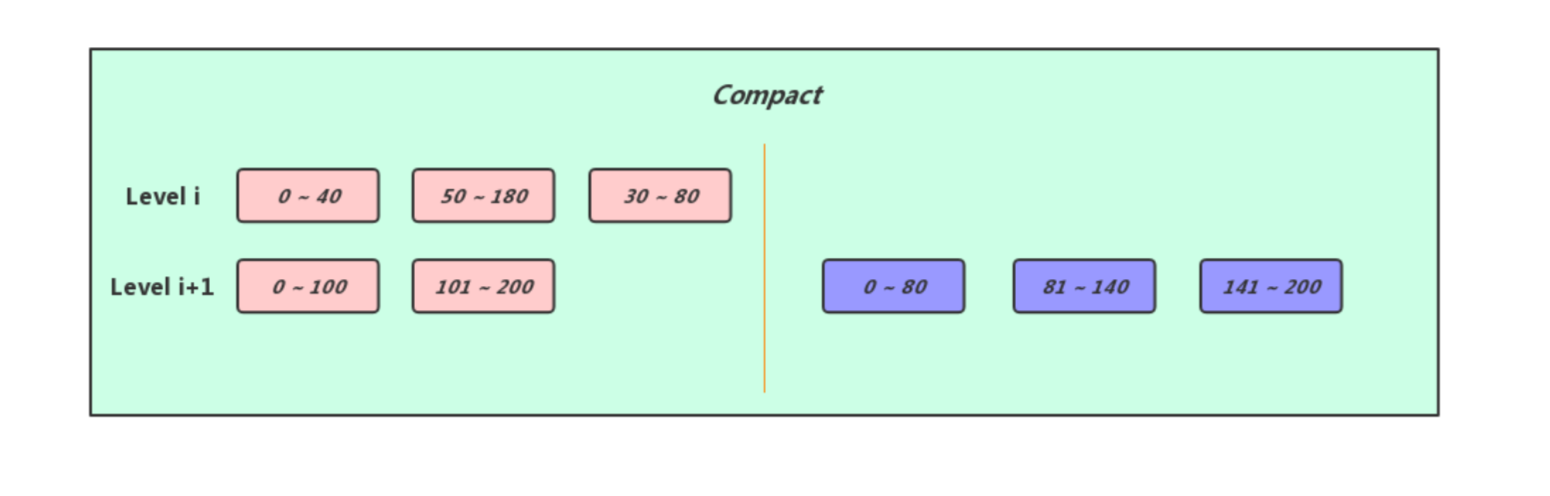
经历过多路合并之后Level i和Level i+1层的sst文件中的有效条目被合并会生成新的sst文件,我们需要将新生成的sst文件放入Level i+i层中合适的位置,然后将之前参与Compact的sst文件删除
经过上一步多路合并的操作,由于我们对Level i层以及Level i+1层的sst文件进行了改动,所以可能会触发新一轮的Size Compaction,这时候我们需要对每一次进行积分统计,从而得出参与新一轮Compact的层数
积分规则十分简单
我们会在新的Version中记录最高的积分以及对应的层数,如果记录的积分大于等于1,则我们会在下次对对应的Level进行Compact操作
Compact我认为是Leveldb最复杂的过程之一,同时也是Leveldb的性能瓶颈之一(compact过程伴随着文件的增删,占据磁盘IO,如果Compact速度过慢导致Level 0层sst文件堆积,可能会触发Leveldb的缓写甚至阻写的机制),但是在执行Compact的期间对Leveldb的可用性不会造成影响,在Compact的过程中虽然会生成新的sst文件,但是旧的sst文件是不会被删除的,这意味着它依然是可读的,只有在Compact结束的时候会将sst文件的改动应用到新的Version上,这时候如果没有快照引用旧sst文件,那么这些旧的sst文件就可以被安全的删除了.